[Python] 투자 포트폴리오 델타-노말/공헌/한계/증분 VaR 구하기

구글 스프레드 시트는 시트를 웹페이지로 변환해 게시할 수 있는 기능이 있어, 이를 이용해 실시간으로 포트폴리오의 구성 종목을 크롤링하여 가져오고 VaR를 계산하는 코드를 작성해 봤다.
먼저, 필요한 기능들을 불러온다.
from selenium.webdriver.common.by import By
from selenium import webdriver
import pandas as pd
import yfinance as yf
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from datetime import datetime, date, timedelta
import scipy.stats as stats
from arch import arch_model
import statsmodels.api as sm
import FinanceDataReader as fdr
다음에는 Selenium의 Webdriver를 사용해서 웹페이지의 데이터를 크롤링하면 된다.
driver=webdriver.Chrome()
driver.get('게시한 스프레드 시트의 주소 넣기')
driver.find_element(By.XPATH,'//*[@id="sheet-button-1233126621"]/a').click() #탭 클릭
처음 웹 페이지를 불러올 때 [주식, 펀드] 탭이 아닌 [포트폴리오(1)] 탭에 들어가므로
Selenium의 Click 기능을 활용해서 [주식, 펀드] 탭을 클릭하는 기능을 구현해줘야 한다.
탭의 Xpath 주소를 넣고 Click을 실행하면 자동으로 [주식, 펀드] 탭을 클릭해서 들어간다.
Data=pd.DataFrame(columns=['종목명','통화','티커','잔고주식수','잔고평가액'],index=range(1,21)) #빈 DataFrame 생성
for i in range(3,20):
종목명=driver.find_element(By.XPATH,'//*[@id="1233126621"]/div/table/tbody/tr[{}]/td[1]'.format(i)).text
통화=driver.find_element(By.XPATH,'//*[@id="1233126621"]/div/table/tbody/tr[{}]/td[3]'.format(i)).text
티커=driver.find_element(By.XPATH,'//*[@id="1233126621"]/div/table/tbody/tr[{}]/td[4]'.format(i)).text
잔고주식수=driver.find_element(By.XPATH,'//*[@id="1233126621"]/div/table/tbody/tr[{}]/td[7]'.format(i)).text
잔고평가액=driver.find_element(By.XPATH,'//*[@id="1233126621"]/div/table/tbody/tr[{}]/td[11]'.format(i)).text
Data.loc[i-2,"종목명"]=종목명
Data.loc[i-2,"통화"]=통화
Data.loc[i-2,"티커"]=티커
Data.loc[i-2,"잔고주식수"]=잔고주식수
Data.loc[i-2,"잔고평가액"]=잔고평가액
Data=Data.fillna(0) #NaN 값을 0으로 대체이후에는 Xpath를 활용해서 데이터를 크롤링한다.
크롤링 이전에 'Data'라는 데이터프레임을 만들어뒀고,
'종목명', '통화', '티커', '잔고주식수', '잔고평가액' 칼럼(열)을 만들어줬다.
'종목명'의 경우
//*[@id="1233126621"]/div/table/tbody/tr[변수가 들어갈 값]/td[1]위의 Xpath 형식을 가지고, tr[ ] 안에 어떤 수가 들어가느냐에 따라 출력되는 종목명이 달라진다.
예를 들어, Xpath가 아래와 같으면
//*[@id="1233126621"]/div/table/tbody/tr[3]/td[1]첫 번째 종목명인 'KODEX 선진국MSCI World'가 출력되고
Xpath가 아래와 같으면
//*[@id="1233126621"]/div/table/tbody/tr[4]/td[1]두 번째 종목명인 'KODEX 미국달러선물레버리지'가 출력된다.
때문에, for 반복문을 활용해서 각 칼럼의 3~20번 행까지 미리 만들어놓은 데이터프레임에 저장해 주는 코드를 만들었다.
Data=pd.concat([Data.loc[:,["종목명","통화"]],
Data.loc[:,"티커"],
Data.loc[:,"잔고평가액"].str.replace(",","").fillna(0),
Data.loc[:,"잔고주식수"].str.replace(",","").fillna(0)],axis=1) #쉼표 제거
Data=Data.loc[Data.loc[:,"잔고평가액"].astype("float")>0,:] #'잔고평가액' > 0 인 행만 추출데이터에 쉼표가 있으면 숫자가 아닌 문자로 인식되는 것 같아 쉼표를 제거하였고,
'잔고평가액'이 0인 종목은 'Data'에서 제거해 줬다.

Returns_all=pd.DataFrame(columns=Data['티커'])
Vol_all=pd.DataFrame(columns=Data['티커'],index=['Equal','Garch'])
for i in range(1,len(Data)+1):
Stock=pd.concat([fdr.DataReader('USD/KRW',start=datetime.today()-timedelta(365*3),end=datetime.now().date())['Close'].resample('M').last(),
fdr.DataReader(Data.loc[i,'티커'],start=datetime.today()-timedelta(365*3),end=datetime.now().date())['Close'].resample('M').last()],axis=1)
if Data.loc[i,'통화']=='USD':
Stock=Stock.iloc[:,0]*Stock.iloc[:,1]
else:
Stock=fdr.DataReader(Data.loc[i,'티커'],start=datetime.today()-timedelta(365*3),end=datetime.now().date())['Close'].resample('M').last()
Series=np.log(((Stock-Stock.shift(1))/Stock.shift(1))+1)
Series=Series[1:] #첫 행 제거
Series=Series.fillna(0) #NaN 값 0으로 바꾸기
Vol_Garch=arch_model(Series,p=1,q=1,vol='GARCH').fit().forecast().variance.iloc[-3:]#GARCH 모델 변동성 계산
Vol_Garch=np.sqrt(Vol_Garch.iloc[0,0])
Vol=np.sqrt(np.var(Series))
Returns_all[Data.loc[i,'티커']]=Series
Vol_all.loc['Equal',Data.loc[i,'티커']]=Vol
Vol_all.loc['Garch',Data.loc[i,'티커']]=Vol_Garch다음은 FinanceDataReader 기능을 활용해서 'Data'의 '티커' 열을 읽고,
각 종목의 주가 데이터를 읽어오는 코딩을 만들었다. (기간은 지난 3년, 주기는 월별 데이터)
그리고 미국에 상장된 ETF의 경우 USD/KRW 환율의 변화도 반영해 주기 위해서
주가 데이터에 각 날짜에서의 USD/KRW를 곱해주었다.
('Data'의 '통화' 열의 값이 'USD'인 경우 USD/KRW를 곱해주는 조건식 작성)
'Series'는 주가 데이터로 월별 주가수익률을 구한 것.
'Vol'은 'Series'를 이용해서 변동성을 구한 것.
'Vol_Garch'는 arch 기능을 활용해서 Garch 시계열 변동성을 구한 것.
각 종목의 월별 주가수익률은 'Returns_all', 변동성은 'Vol_all'에 저장해 줬다.

Equal은 모든 기간을 동일하게 가중하여 도출한 변동성
Garch은 시계열을 고려한 변동성
포트폴리오 VaR을 구하기 위해서 상관계수 행렬 구하기.
CORR=pd.DataFrame(columns=Data['티커'],index=Data['티커'])
for i in range(0,len(Data)):
for j in range(0,len(Data)):
R=Returns_all.iloc[:,j].to_numpy()
C=Returns_all.iloc[:,i].to_numpy()
CORR.iloc[i,j]=np.corrcoef(R,C,ddof=1)[0,1]먼저 상관계수를 저장해 줄 데이터프레임을 만든다.

다음으로 i, j 두 변수로 중첩된 반복문을 만들어 총 5x5=25개의 상관계수를 구한 뒤 저장한다.

USDKRW=fdr.DataReader('USD/KRW')['Close']
USDKRW=USDKRW.iloc[len(USDKRW)-1]
Transpose=Vol_all.iloc[1,:].astype('float').transpose()
Transpose.index=range(1,len(Transpose)+1)
VaRs=1.65*Data.iloc[:,3].astype('float')*Transpose
VaRs=pd.concat([VaRs,Data['통화']],axis=1)
VaRs=VaRs.rename(columns={0:'VaR'})
VaRs.loc[VaRs['통화']=='USD','VaR']=VaRs['VaR']*USDKRW본격적으로 델타-노말 VaR (95%) 구하기

'투자금액'과 '변동성'을 곱해줄 때 방향이 맞지 않아서 'Transpose' 기능을 사용했다.
그리고 미국 ETF는 USD로 VaR를 측정하게 되므로 현재 USD/KRW 환율을 곱해줬다.

각 종목의 VaR를 이용해 포트폴리오 전체의 VaR 구하기
#포트폴리오 VaR
CORR_array=CORR.to_numpy()
VaR_array=VaRs.iloc[:,0].to_numpy()
VaR_Portfolio_1Month=np.sqrt(np.dot(np.dot(VaR_array,CORR_array),VaR_array))numpy 기능의 np.dot()을 활용해 행렬을 곱할 수 있다.

(1x5)*(5x5)*(5x1)=(1x1) → 행렬 3개를 곱하여 하나의 값이 나온다.

#공헌 비율
ContributionRatio=(np.dot(VaR_array,CORR_array)*VaR_array/(VaR_Portfolio_1Month**2))
#공헌 VaR
VaR_Contribution=(np.dot(VaR_array,CORR_array)*VaR_array/(VaR_Portfolio_1Month**2))*VaR_Portfolio_1Month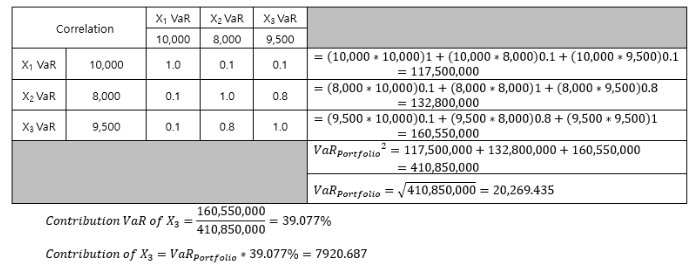
공헌 VaR을 구하는 방식은 위의 이미지를 참고.
#Marginal VaR
Data_Marginal=Data.loc[:,['잔고평가액','통화']]
Data_Marginal.loc[Data_Marginal['통화']=='USD','잔고평가액']=USDKRW*Data_Marginal['잔고평가액'].astype('float')
VaR_Marginal=pd.DataFrame(columns=['Marginal VaR'],index=range(0,len(Data)))
VaR_Marginal=(VaR_Contribution/Data_Marginal['잔고평가액'].astype('float'))한계 VaR의 경우 공헌 VaR을 투자 금액으로 나누어 구할 수 있다.
#Incremental VaR
VaR_Incremental=pd.DataFrame(columns=['Incremental VaR'],index=range(1,len(Data)+1))
for x in range(1,len(Data)+1):
Data_Incremental_VaR=Data.drop(x,axis=0)
Data_Incremental_VaR.index=range(1,len(Data_Incremental_VaR)+1)
Returns_all=pd.DataFrame(columns=Data_Incremental_VaR['티커'])
Vol_all=pd.DataFrame(columns=Data_Incremental_VaR['티커'],index=['Equal','Garch'])
for i in range(1,len(Data_Incremental_VaR)+1):
Stock=pd.concat([fdr.DataReader('USD/KRW',start=datetime.today()-timedelta(365*3),end=datetime.now().date())['Close'].resample('M').last(),
fdr.DataReader(Data_Incremental_VaR.loc[i,'티커'],start=datetime.today()-timedelta(365*3),end=datetime.now().date())['Close'].resample('M').last()],axis=1)
if Data_Incremental_VaR.loc[i,'통화']=='USD':
Stock=Stock.iloc[:,0]*Stock.iloc[:,1]
else:
Stock=fdr.DataReader(Data_Incremental_VaR.loc[i,'티커'],start=datetime.today()-timedelta(365*3),end=datetime.now().date())['Close'].resample('M').last()
Series=np.log(((Stock-Stock.shift(1))/Stock.shift(1))+1)
Series=Series[1:] #첫 행 제거
Series=Series.fillna(0) #NaN 값 0으로 바꾸기
Vol_Garch=arch_model(Series,p=1,q=1,vol='GARCH').fit().forecast().variance.iloc[-3:]#GARCH 모델 변동성 계산
Vol_Garch=np.sqrt(Vol_Garch.iloc[0,0])
Vol=np.sqrt(np.var(Series))
Returns_all[Data_Incremental_VaR.loc[i,'티커']]=Series
Vol_all.loc['Equal',Data_Incremental_VaR.loc[i,'티커']]=Vol
Vol_all.loc['Garch',Data_Incremental_VaR.loc[i,'티커']]=Vol_Garch
CORR=pd.DataFrame(columns=Data_Incremental_VaR['티커'],index=Data_Incremental_VaR['티커'])
for i in range(0,len(Data_Incremental_VaR)):
for j in range(0,len(Data_Incremental_VaR)):
C=Returns_all.iloc[:,i].to_numpy()
R=Returns_all.iloc[:,j].to_numpy()
CORR.iloc[i,j]=np.corrcoef(R,C,ddof=1)[0,1]
Transpose=Vol_all.iloc[1,:].astype('float').transpose()
Transpose.index=range(1,len(Transpose)+1)
VaRs_Incremental=1.65*Data_Incremental_VaR.iloc[:,3].astype('float')*Transpose
VaRs_Incremental=pd.concat([VaRs_Incremental,Data_Incremental_VaR['통화']],axis=1)
VaRs_Incremental=VaRs_Incremental.rename(columns={0:'VaR'})
VaRs_Incremental.loc[VaRs_Incremental['통화']=='USD','VaR']=VaRs_Incremental['VaR']*USDKRW
CORR_array=CORR.to_numpy()
VaR_Incremental_array=VaRs_Incremental.iloc[:,0].to_numpy()
VaR_Portfolio_1Month_Incremental=VaR_Portfolio_1Month-np.sqrt(np.dot(np.dot(VaR_Incremental_array,CORR_array),VaR_Incremental_array))
VaR_Incremental.iloc[x-1,0]=VaR_Portfolio_1Month_Incremental증분 VaR은 구하기가 복잡하다.
해당 종목이 없을 때의 VaR과 있을 때의 VaR의 차이를 구해야 한다.
가장 큰 for문에서는 전체 종목에서 순차적으로 한 종목씩 제외한다. (drop 함수 사용)
그 후의 코드들은 앞서해왔던 과정들을 다시 반복하여 한 종목을 제외한 VaR를 구한다.
(5개 종목 중 한 종목을 제외하고, 4개의 종목으로 상관계수, VaR을 구하여 4개 종목으로만 전체 VaR 도출)
이렇게 한 종목씩 증분 VaR을 구하고, 이를 여러 번 반복해 모든 종목의 증분 VaR을 구한다.
#최종 정리
Final=pd.DataFrame(index=range(1,len(Data)+1),columns=["종목명","티커","VaR","공헌VaR","공헌비율","Marginal VaR","Incremental VaR"])
Final.iloc[:,0]=Data.iloc[:,0] #종목명
Final.iloc[:,1]=Data.iloc[:,2] #티커
Final.iloc[:,2]=VaRs.iloc[:,0].apply(lambda x:f"{x:,.0f}") #델타-노말 VaR
Final.iloc[:,3]=pd.DataFrame(VaR_Contribution).iloc[:,0].apply(lambda x:f"{x:,.0f}") #공헌 VaR
Final.iloc[:,4]=pd.DataFrame(ContributionRatio).iloc[:,0].apply(lambda x:f"{x:10.2%}") #공헌 비율
Final.iloc[:,5]=VaR_Marginal.apply(lambda x:f"{x:,.4f}") #Marginal VaR
Final.iloc[:,6]=VaR_Incremental.iloc[:,0].apply(lambda x:f"{x:,.0f}") #Incremental VaR마지막으로 모든 결과를 'Final'이라는 데이터 프레임에 정리하기.
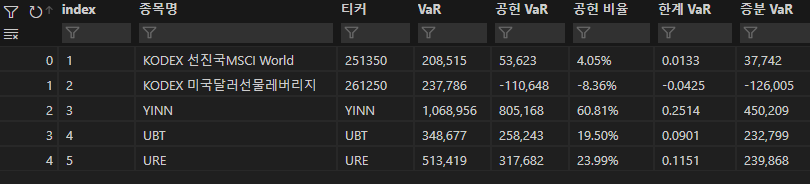
포트폴리오에서 위험 헷지용으로 투자하고 있는 'KODEX 미국달러선물레버리지'
채권의 경우도 전체 기간으로 보면 주식과 굉장히 낮은 상관관계를 지니고 있지만,
2022년처럼 시장 전체의 유동성이 줄어드는 시기에는 둘 다 가격이 하락한다.
하지만, USD/KRW 환율은 주식, 채권 모두와 음의 상관관계를 지니고 있고, 2022년에도 이러한 관계를 유지해 왔다.
VaR 데이터를 보면 'KODEX 미국달러선물레버리지'는 전체 포트폴리오의 VaR를 줄이는 것에 공헌하고 있기에 헷지용 자산으로써 의미가 있다.